TWITTER
TWITTER
 FACEBOOK
FACEBOOK
 はてブ
はてブ

2024年2月16日、遂にGoogleの新型AIモデル「Gemini」が「Gemini 1.5」へとアップデートされました。
「Gemini」とは、Googleが開発した最新のAIモデルで、テキストだけでなく、画像や音声などのマルチモーダルデータ処理に特化しています。
本記事では、Gemini 1.5になって何が進化したのか、代表的なAIモデル「GPT-4(ChatGPT)」との比較を通して解説していきます。
ChatGPTを超えるとも言われている「Google Gemini 1.5」は、今後のビジネスシーンでも多く耳にするはずです。
本記事を通して最新のAIについての動向をサクッと理解していきましょう!
<この記事を読むとわかること>
- そもそもGeminiとは何か
- Gemini1.5のバージョンアップした点
- Gemini 1.5とその他のAIモデルとの詳細な比較
- Gemini 1.5の使い方
<あわせて読みたい!!>

目次
|Googleの新型AIモデル「Gemini 1.5」とは?

| 詳細 | |
| モデル名 | Google Gemini 1.5 |
| 発表日 | 2024年2月16日 |
| 開発者 | Google DeepMind |
| アーキテクチャ | Mixture-of-Experts (MoE) |
| 処理能力 | 最大100万トークンの連続処理が可能 |
| 主な機能 | 長文の理解、大量のコンテンツの分析・分類・要約、複数モダリティ間の推論能力 |
| 利用可能プラットフォーム | Vertex AI、AI Studio |
| 対象ユーザー | 開発者、エンタープライズユーザー、将来的には一般消費者も対象 |
| 公式リンク | https://gemini.google.com/ |
Google Gemini 1.5は、Googleによって2024年2月16日に発表された最新のAIモデルです。
これまで多くの人々が利用してきた「ChatGPT」がAI技術の代名詞となっている中、Gemini 1.5はその限界を超える可能性を秘めていることで大きな注目を集めています。
Gemini 1.5は、AIが取り扱える情報量の限界を大幅に拡張し、最大100万トークンの連続処理能力を持ちます。
これにより、従来のAIでは解決が困難だった複雑な問題への対応や、新しいアプリケーションの開発が可能になります。
また、Gemini 1.5は、例えばアポロ11号の月面着陸に関する記録や、バスター・キートンの無声映画など、大量のコンテンツをシームレスに分析、分類、要約することも可能です。
そのため、膨大な情報から重要な点を抽出し、新しい知見を生み出すことも期待できます。
今後、GoogleはGeminiを基盤としてAIの能力をさらに拡張し、新しいアプリケーションやサービスの開発を進めていく予定です。

「Google Gemini」のおさらい
Google Gemini 1.5について詳しく見ていく前に、現行モデルの「Gemini」について簡単におさらいしておきましょう。
GeminiはGoogleが開発した最新のAIモデルで、テキスト、画像、オーディオ、ビデオなど、さまざまな種類の情報を一括して理解し、処理できる能力を持つ点が特徴です。
2023年12月6日に発表され、既に利用可能な状態となっています。
「Ultra」、「Pro」、「Nano」という3つのバリエーションで展開され、それぞれ異なるタスクに対する最適化が図られています。
特に「Ultra」バージョンは、複雑な言語理解テストで人間の専門家を超える性能を示しており、AI技術における新たなマイルストーンを打ち立てました。
非常に高性能のAIモデルであったため、発表約3ヶ月後の2024年2月9日には加入者数が1億人を突破。
最新バージョンのリリースを望む声も強まる中、満を持してGemini 1.5をリリースした形です。
Google Geminiの凄さが体感できる動画
Geminiについての凄さを体感するために、まずは動画を見てみるとわかりやすいです。
上記の動画は、Googleが公式に発表した動画の一つです。
本動画では、Geminiが画面上に次々に現れるオブジェクトを瞬時に把握し、その様子をテキストで説明する様子が見られます。
ご覧いただければわかるかと思いますが、ほとんど人間の認識速度と変わらない速度でオブジェクトを正確に言い当てています。
例えば、青い鴨の絵を書いている途中にそのオブジェクトが「鴨」であることを認識していたり、世界地図で指をさした地域の国名を瞬時に回答したりと、Geminiの正確性が如実に体感可能です。
GPT-4にも画像認識機能は搭載されていますが、認識にかなり時間がかかる(画像によっては1分ほどかかる)のが問題点でした。
しかしこの動画をみる限り、少なくとも画像認識速度ではGPT-4を超えていると見ても良いかもしれません。
Google Gemini 1.5 Proの料金は未定
Google Gemini 1.5は、開発者や企業向けにGoogle AI StudioやVertex AIを通じて現在テスターとして無料で利用可能です。
(※Google AI StudioやVertex AIの使い方は後述)
一般ユーザーが使えるようになるのは、公開テスト終了後となります。
Gemini 1.5 Proは、初期段階では12800トークンまで無料で使用でき、それ以上の使用には料金が発生するプランが検討されているようです。
Google Geminiは無料で利用可能!
なお、現行版のGeminiであれば既に利用可能です。
無料版は日本語対応で、230以上の国で利用可能です。
一方、Advancedプランは月額2,800円で、英語のみの対応となりますが、複雑な言語処理やマルチモーダルなコンテンツ生成など高度な機能を提供します。
無料版と有料版の詳しい違いについては以下の表をご確認ください。
| 無料版 | 有料版 | |
| バージョン名 | Gemini 1.0 Pro (Free tier) | Gemini Advanced with Ultra 1.0 |
| 月額コスト | 無料 | ¥3008.10/月 |
| プランに含まれる内容 | 基本AI機能 | 最新AI進歩、Google One Premium利益 |
| ストレージ | N/A | 2TB |
| レート制限 | 60 QPM (クエリ/分) | 60 QPMを超える |
| テキスト入力価格 | 無料 | ¥0.01881 / 1K文字 |
| 画像入力価格 | 無料 | ¥0.37620 / 画像 |
| テキスト出力価格 | 無料 | ¥0.05643 / 1K文字 |
| 高度なコーディングサポート | 限定 | 拡張機能付きで提供 |
| 追加AI機能 | 限定 | 拡張マルチモーダル機能、より深いデータ分析等 |
| Googleサービスでの使用 | 限定 | 近々Gmail、Docs、Slides、Sheets等で利用可能 |
(※為替レートを1ドル=150円で算出しています)
|Google Gemini 1.5の進化した特徴3つ
では具体的に、Googleの新型AIモデル「Gemini 1.5」は現行モデルと比較して何が進化したのでしょうか。
ここでは、Google Gemini 1.5の進化点を3つ詳しく解説します。
①最大100万トークンまで拡大し長文理解能力が大幅に向上
Google Gemini 1.5の進化点の1つ目は、「トークン数」の増加です。
AIモデルにおける「トークン数」とは、AIが一度に読み取り、理解できるデータの量を指します。
文字や単語、句読点など、情報を小さな単位に分けたものが「トークン」です。
例えば「太陽が綺麗ですね」という文は、「太陽」「が」「綺麗」「です」「ね」という5つのトークンに分けられます。
それぞれの単語や句読点が1つのトークンとしてカウントされるわけです。
Google Gemini 1.5では、このトークン数を大幅に拡張しています。
標準構成でさえ、Gemini 1.0の3万2000トークンを超える12万8000トークンを扱うことができ、応答生成時の情報量(コンテキストウィンドウ)を最大100万トークンまで拡張しています。
これにより、より長い文書や複雑な情報も一度に理解できるようになりました。
具体的には、100万トークンというのは、1時間のビデオ、11時間の音声、3万行以上のコード、または70万語以上の単語など、非常に膨大な情報量を一度に処理できることを意味します。
例えば、アポロ11号の月面着陸に関する402ページに及ぶ記録を与えた場合でも、その文書内の会話や出来事、詳細について理解し、推論することが可能になります。
このように、Google Gemini 1.5は、より多くの情報を一度に処理できるようになったことで、長文や複雑な情報を理解する能力が大幅に向上しました。
②新しいMoEアーキテクチャを採用
Google Gemini 1.5の進化点の2つ目は、新しいMoE(Mixture of Experts)アーキテクチャを採用している点です。
まず、「アーキテクチャ」というのは簡単にいえば、AIがどのように情報を処理し、学習するかの「設計図」のようなものです。
建物がどのように構築されるかを決める建築設計と似ており、AIの性能や能力に直接影響を与えます。
例えば、ChatGPTではTransformerアーキテクチャを採用していますが、これは主に連続したテキストデータを処理するのに適しており、一般的な会話や文章生成に強みを持っています。
一方で、MoEアーキテクチャは、さまざまな種類の問題に対してより柔軟に対応することができるため、Google Gemini 1.5は多様なタスクやより複雑な問題に対しても高い性能を発揮することが可能です。
そのため、Google Gemini 1.5は、単にテキストを理解するだけでなく、様々なタイプのデータを柔軟に扱い、多様な問題に対して高い精度で対応することができるのです。
③新フィルターを搭載し安全性を向上
Google Gemini 1.5の進化点の3つ目は、新フィルターを搭載したことによる安全性の向上です。
生成AI(ジェネレーティブAI)というのは、テキストや画像などを自動で生成する技術ですが、その性質上セキュリティリスクを常に抱えています。
例えば、不適切なコンテンツの生成や、著作権に触れる素材の無断使用など、様々な問題が発生する可能性があるのです。
生成AIをビジネスシーンで利用するには、これらのセキュリティの問題をクリアしなければなりません。
その点、Google Gemini 1.5は新しいフィルターを搭載することによって、これらのセキュリティリスクを軽減しています。
この新しいフィルターを通して生成された画像に「SynthID」と呼ばれる識別可能な「透かし」を埋め込むことで、AIによって作成された作品と人間による作品を明確に区別します。
また、Googleは技術的な保護機能にも注力しており、暴力的、攻撃的、または露骨な性的コンテンツの生成を制限するフィルターも設計中です。
さらに、著名人の画像の生成を避けるように特別に設計されたフィルターも採用されています。
|Google Gemini 1.5とGPT-4(ChatGPT)を徹底比較!
2024年現在では、Gemini 1.5の他にも「ChatGPT」「BingAI」など、大手ITテックがリリースしているAIモデルもたくさんあります。
現状、ChatGPTの一人勝ちともいえる様相を呈していますが、今後は用途によって生成AIを使い分ける必要性も出てくるでしょう。
各モデルによって得意領域や性能も大きく変わってくるので、Gemini 1.5をベースとして代表的なAIモデルであるGPT-4(ChatGPT)との性能を以下で比較します。
GPT-4(ChatGPT) VS Google Gemini 1.5
| Google Gemini 1.5 | ChatGPT (GPT-4) | |
| パラメータ数(モデルサイズ) | Ultra: 1.56兆 Pro: 6000億 Nano: 18億 | 約100兆個 |
| トークン数 | 128,000(実験的には最大1,000,000) | 標準8,000、拡張32,000 |
| トレーニングデータ | 非公表 | インターネット上の広範なテキストデータ (トレーニングに10兆トークン使用) |
| 性能指標 | MMLUで90.0%(人間の専門家を上回る)、Big-Bench Hardで83.6%の正確さ | 多くのベンチマークで高い性能、特定のベンチマークで人間を超えることもあり |
現状のスタンダードともいえるGPT-4、つまりChatGPTとGoogle Gemini 1.5を比較していきましょう。
GPT-4(ChatGPT)とは?
GPT-4(ChatGPT)は、OpenAIによって開発された最新の自然言語処理AIモデルです。
GPT-4は、その前身であるGPT-3やGPT-3.5よりもさらに進化しており、テキストを生成する際の精度が高くなっています。
つまり、誤字脱字が減り、より複雑な指示にも対応できるようになったのです。
また、GPT-4の大きな進歩として「マルチモーダル」能力が挙げられます。
これは、テキストだけでなく、画像や音声などの異なる形式のデータも理解できるようになったということです。
野村総合研究所(NRI)の最新の調査によれば、日本での認知度は約69%、利用率は約15%と、現状最も日本で使用されている生成AIツールになります。
パラメータ数(モデルサイズ)の比較
パラメータ数(モデルサイズ)で比較すると、現状ではGPT-4(ChatGPT)の方が優勢です。
AIモデルにおけるパラメータ数とは、そのモデルが学習過程で調整することができる重みの総数を指します。
パラメータ数が多いほど、モデルはより複雑なデータパターンを捉え、より細かいニュアンスを理解する能力が高まる可能性が高いです。
つまり、パラメータ数が多いモデルは、言語の微妙な意味の違いや、複雑な文脈関係をより正確に理解し、反映することができるようになります。
GPT-4(ChatGPT)のパラメータ数が約100兆個であることに対し、Google Gemini 1.5の最大のモデル(Ultra)は1.56兆個のパラメータです。
したがって、理論上はGPT-4がより複雑な言語のニュアンスを捉え、より洗練されたレスポンスを生成する能力を持つことを示唆しています。
トークン数の比較
トークン数で比較すると、Google Gemini 1.5の方が高いです。
トークン数とは簡単にいえば、AIが一度に読み取り、理解し、反応できる単語やフレーズの「量」です。
人間の会話で例えるなら、一度にどれだけの情報を処理し、理解できるかという能力に相当します。
Google Gemini 1.5は、128,000トークンという非常に高い基本的なトークン数を持ち、さらに実験的には最大1,000,000トークンまで処理できると報告されています。
これに対して、GPT-4(ChatGPT)の標準的なトークン数は8,000で、特定の条件下では32,000トークンまで拡張可能です。
したがって、Google Gemini 1.5はその高いトークン数により、特に長文の理解や生成において強みを持つと言えるでしょう。
性能指標(ベンチマーク)の比較
性能指標(ベンチマーク)で比較すると、一概にはいえませんが、Google Gemini 1.5の方が若干上回っているかもしれません。
例えば、推論と数学のタスクでは、Geminiが32のアカデミックベンチマークのうち30で最先端の性能を達成しています。
また、マルチモーダリティ(テキスト、画像、音声など複数のデータ形式を扱う能力)に関しても、GeminiはGPT-4より優れていると報告されています。
特に、ビジュアルやオーディオ、ビデオのベンチマークでGPT-4を上回ることに成功し、最大で10%の性能向上を達成しました。
コーディングの分野でも、GeminiはGPT-4を凌駕する結果を示し、複雑なコーディング問題を解決する能力を測定するテストでは、Geminiがより高い精度でタスクを完了させることができたとのことです。
しかし、これはある特定のタスクや条件下でのベンチマークであり、全ての実用的なシナリオでの性能を決定づけるわけではありません。
総括:Google Gemini 1.5の方が総合力は高い
GPT-4はテキスト生成の精度と多様なデータ形式の理解能力で優れている一方で、Google Gemini 1.5はトークン数の多さや特定の性能指標での優位性を示しています。
特に、Google Gemini 1.5は長文の理解や生成、ビジュアルやオーディオ、ビデオなどのマルチモーダルなタスクにおいて、その能力を発揮することが期待されています。
一方、GPT-4はテキストベースのコミュニケーション、教育、コンテンツ生成、翻訳などの分野で引き続き強力なツールであり続けるでしょう。
その高い言語理解能力と精度は、ユーザーが求める質の高いテキスト生成に不可欠です。
結論として、どちらのモデルが「最適」かというのは、使用するシナリオや必要とするタスクの性質に大きく依存します。
Google Gemini 1.5の期待値が高い一方で、GPT-4の堅牢なテキスト生成能力も無視できません。
今後は、これらのAIモデルを単独で使用するのではなく、プロジェクトやタスクの目的に応じて適切に組み合わせて使用することが求められます。
例えば、初期のアイデア生成やドラフト作成にはGPT-4を使用し、その後の内容の拡充やマルチメディア要素の追加にはGeminiを利用するといった形です。
これにより、AIの能力を最大限に活用し、より複雑で高度な作業を効率的に遂行することが可能になるでしょう。

|Google Gemini 1.5の使い方
このように、非常に高いパフォーマンスを示すGoogle Gemini 1.5ですが、実際に使用するにはどうすれば良いのでしょうか。
ここでは、2024年2月時点でのGemini 1.5の使い方についてご紹介します。
Google AI Studioを通して利用できる
Google Gemini 1.5を使うには、Google AI StudioかVertex AIを通してGemini 1.5 Proを利用できます。
ただし、現在はまだテスト段階であり、あくまでテスターとして利用することになります。(料金は無料)
Google AI Studioとは、開発者がGeminiモデルを利用して、アプリケーションやサービス内で直接AI機能をプロトタイプ作成し、テストすることができるWebベースのツールです。
コードを書くことなく直感的なインターフェースを通じてAIモデルと対話し、その結果をリアルタイムで確認することができます。
PDFファイル、コードリポジトリ、長時間の動画など、様々な形式のデータをアップロードして、それに関する質問をすることも可能です。
以下に、Google AI Studioの始め方について簡単に紹介するので、興味のある方はテスターとして参加してみましょう。
Google AI Studioを通した始め方
Google Gemini 1.5をGoogle AI Studioを通して始める方法は以下の通りです。
<STEP1>

まずは、(https://ai.google.dev/)にアクセスします。
<STEP2>
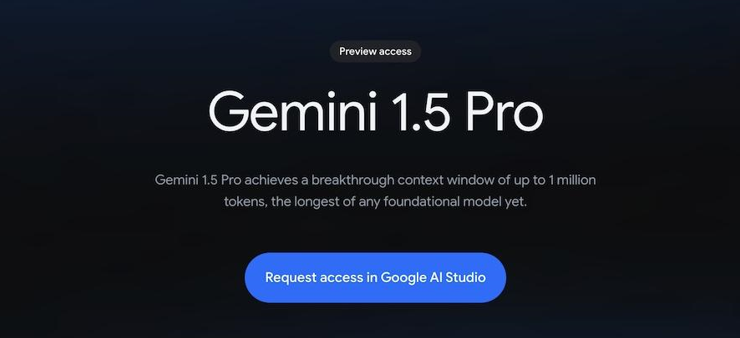
画面を少し下にスクロールすると、上記のボタンがあるので「Request access in Google AI Studio」を押下してください。
<STEP3>
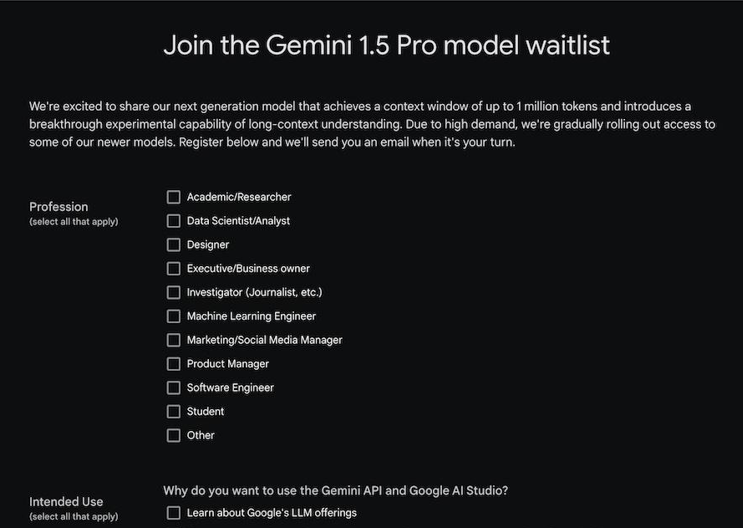
上記の回答フォームに遷移するので、該当するProfession(役職)とIntended Use(使用目的)をチェックしましょう。
<STEP4>
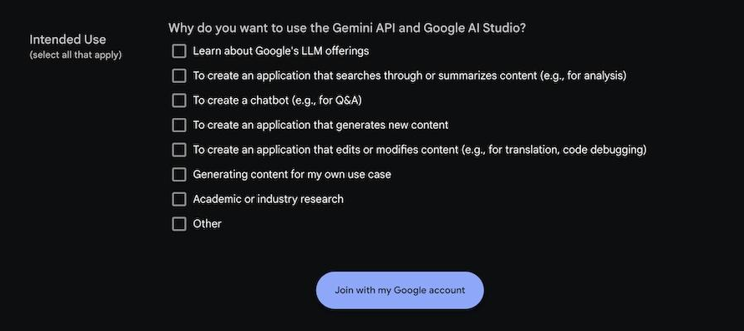
フォーム画面最下部に「Join with my Google account」というボタンがあるので押下してください。
(※Google accountが無い場合はエラーになります)
<STEP5>
正式に認証されると上記の画面に遷移するので、これでテスターのウェイトリストに正式に参加しました。
ウェイトリストなので、正式に使用できるようになるには時間がかかるので注意してください。
Google Gemini 1.5はかなり注目のAIモデルなので、2、3日待っても使えないという報告もあります。
こればかりは、サーバーの負荷状況なども関係しているので現状では待つしかありません。
やはり、一般ユーザー向けの公開が待ち遠しいところです。
Google APIキーの取得方法
一般的に、AIモデルを使用するには「APIキー」というものが必要です。
API(Application Programming Interface)というのは、異なるソフトやアプリ間で機能や情報などを共有するためのツール(正式にはインターフェース)のようなものです。
既存のサービスを組み合わせて、新しいアプリや機能を作り出す際によく使用されます。
APIキーというのは、このAPIを使用するためのパスワードのようなものです。つまり、APIキーが無いとAPIを使用することはできません。
例えば、GPT-4(chatGPT)などのAIモデルを使用する際にもAPIキーが必要になるのですが、手順がやや複雑で慣れていない人はこの段階で諦めてしまう方も多いです。
しかし、Google Gemini 1.5はAPIキーを取得するのが非常にシンプルです。
先述したGoogle AI Studioのホーム画面上に「Get API Key」というボタンがあるので、それをクリックするだけでAPIキーが取得できます。
こうすることで、Gemini APIを使用してアプリケーションにGeminiを統合することも可能です。
現状Gemini APIで使用できるプログラミング言語やフレームワークは以下の通りです。
<Gemini APIで使用可能な言語とフレームワーク>
- Python
- Android(Kotlin)
- Dart(Flutter)
- Go
- Node.js
- Swift
|まとめ:Google Gemini 1.5はChatGPTを超えるかもしれない
本記事では、Googleの新型AIモデル「Gemini 1.5」の現行モデル「Gemini」との変更点やその特徴をGPT-4(ChatGPT)との比較を通して解説しました。
Gemini 1.5 VS GPT-4(ChatGPT)論争はしばらく続くことが予想されますが、個人的にはケースバイケースで使い分けるのが良いと思います。
GPT-4(ChatGPT)は既に多くの企業で導入が進んでいるため、この牙城を崩すのは容易なことではありません。
Googleももちろんそれは理解しているはずなので、GPT-4(ChatGPT)とは別路線で攻めてくるでしょう。
Geminiの情報が更新され次第、続報記事を出すつもりなので今後も「メタバース相談室」をご愛読くださいませ。
それでは、また別の記事でお会いしましょう。今回も最後までお読みいただきありがとうございました!
<あわせて読みたい!!>